
Metaphors We Live By
Copyright 1980, University of Chicago Press
Cultural Analysis
“For us, meaning depends on understanding. A sentence can’t mean anything to you unless you understand it.” [Metaphors We Live By, p184]
As I was drawing towards the end of the excellent book Metaphors We Live By, I kept reflecting on this current period of ML tool explosion (I refuse the term AI, this post explains why, and refer to them as ML tools, which encompasses things like ChatGPT for textual output, or Midjourney and DALL•E for image outputs). I am far from the only one thinking about this topic these days. It seems like everyone is talking about “AI,” whether hyping it up, discussing the risks, or just playing with the tools. Two pieces I keep mulling over are Ted Chiang’s ChatGPT is a Blurry JPEG of the Web, and Danilo Campos’ Retrospective of a dying technology cycle, part 4: what comes next?. Both writers are trying to help us make sense of what these ML tools are, and start poking at what exactly changes in the world now that we have them. Chiang explores ML tools via a pixelated image analogy to explain their outputs.
Think of ChatGPT as a blurry JPEG of all the text on the Web. It retains much of the information on the Web, in the same way that a JPEG retains much of the information of a higher-resolution image, but, if you’re looking for an exact sequence of bits, you won’t find it; all you will ever get is an approximation. But, because the approximation is presented in the form of grammatical text, which ChatGPT excels at creating, it’s usually acceptable. You’re still looking at a blurry JPEG, but the blurriness occurs in a way that doesn’t make the picture as a whole look less sharp.
Campos’ piece conceptualizes these ML tools as a “pattern synthesis engine.”
I’m more comfortable calling “AI” a “pattern synthesis engine” (PSE). You tell it the pattern you’re looking for, and then it disgorges something plausible synthesized from its vast set of training patterns.
The pattern may have a passing resemblance to what you’re looking for.
But even a lossy, incomplete, or inaccurate pattern can have immediate value. It can be a starting point that is cheaper and faster to arrive at than something built manually.
Each of these essays are written by people who have spent time to understand the domain, to understand what the Machine Learning process involves, and what is actually being output by these tools. That’s partly why their essays are so helpful to me. But as I read Metaphors We Live By and thought about these pieces in light of the book’s arguments, I realized that what’s most interesting to me is how much work anyone needs to do in order to make sense of ML tools in this way. Tools like ChatGPT and Midjourney are certainly more powerful than any generative software tools that have come before them. Their power is what is leading to the hype cycle; with the current tools you can generally get an output that makes sense in light of your input, in a way that feels straight out of science-fiction. But the outputs cannot be fully trusted; they are often mostly accurate but not fully accurate. This is, to me, the very challenging part about making sense of these tools. In areas where close-enough is fine, they are amazing. In areas where accuracy is necessary, they are fairly useless.
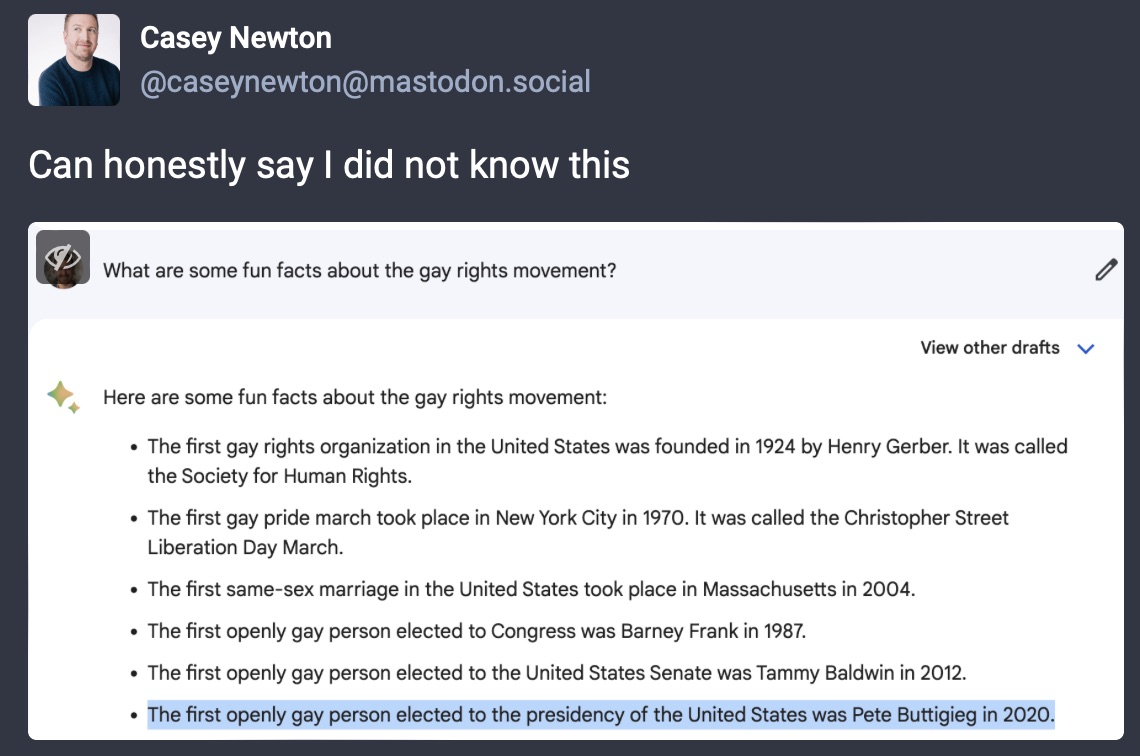
Chiang and Campos and many many others are putting in the work to understand the mechanics of these tools to help them understand why the outputs are the way they are. This information is helpful for understanding why an output might include false or inaccurate information. But these tools are being released on the internet to anyone who wants to use them, with no requirement that a user understand how Machine Learning works at a technical level, nor any real guidance on how to contextualize a given output. Interacting with ML tools can feel like magic. People with no illustration skills can suddenly have a computer generate images they want just by describing them. Writing large amounts of content is as simple as providing a sentence or two of instructions. This is undeniably cool and interesting, but right now, I’m wrestling with this: how will individuals make sense of these new tools, which are powerful in science-fiction ways, but inaccurate in very confusing ways?
The magic of ML tools is that at an impressive level, what you ask for is what the tool will produce. It is very exciting to request it generate a thing, and then see it spit out the thing you described. Finally, we have made computer tools that actually do the work for us, just like SciFi has promised for a century (or more).
Except, there’s a complication. The magic of seeing an output that matches our input is easy to interpret as the computer understanding our intent and responding with what it thinks best matches the request. The chat-box input design for many of the tools builds on this feeling, tapping into our design understanding of a conversational interface. But this is false. ML tools are unable to understand us at all, in any way that we concieve of other humans understanding us.
When we ask of a text-producing ML tool (like ChatGPT) to “tell me the key events from the 1960’s civil rights movement,” it could very well return a fairly accurate list of events. It’s just as likely, however, the list of events will not be fully accurate, or might include completely untrue information. That’s due to the ML tools’ lack of capacity for human-style understanding.
A human might break down the above request based on concepts; the “1960’s civil rights movement” describes a specific time period in which Black Americans fought and protested for the US State to give them equal protections under the law, a thing they had been denied to all Black people since before the nation officially existed. “Key events” is understood as “specific events that are understood historically to have had outsize impact during the period.” A human being asked this question who is familiar with the history might think to list events like MLK’s assassination, the Montgomery Bus Boycott, or the March on Washington, among many other options. A human will thus understand the input at a conceptual level and attempt to create an accurate response that fulfills the question based on their knowledge of the subject.
ML tools do not do any of this, in this way. They can not make sense of the world through concepts and language, they cannot reflect on the question and choose how to answer it. Instead, prior to release, the ML tool was given a massive corpus of textual data, which it processed through algorithmically, finding mathematical associations between words in the text. The amount of text something like ChatGPT is trained on is genuinely mind-blowing. This sorting and analysis happens during the “training” phase and is complete by the time tool is accepting input. The input phrase “1960’s civil rights movement” will have lots of textual associations in the training data, as will “key events” and the ML tool will sort through its database of mathematical associations to respond with key events (probably structured as a list, as most “key events” texts might be) that are statistically likeliest to be correlated to the words in the input. The output is just math, and if it’s accurate it’s only because all of the data fed to the model during training was also accurate, leading to statistical associations that are accurate. If it’s inaccurate, the ML tool contains no “intelligent” ability to question the output, make sense of the words, or catch errors in the text it generates. At no point has the ML model identified key concepts or made conscious decisions about how to respond. It has simply parsed the input based on training, and then responded with the most likely series of words that correlate to the parsed input.
This risk of inaccurate outputs is therefore a direct consequence of the disconnect between how human communication works and how ML algorithms parse an input to generate an output. Humans communicate with intent, and expect other humans to make sense of their intent, towards the goal of understanding. ML tools scan text, and do a bunch of mathematical correlations based on analyzed training data, then return the likeliest result. This means it’s not just in the user experience that the false sense of understanding exists. It exists at the algorithmic level. The fascinating thing is this isn’t accidental. These tools are designed this way because there are longstanding, inaccurate beliefs that these algorithms actually are an accurate representation of human communication.
In Metaphors We Live By, the authors propose a new theory of truth that they argue stands against longstanging competing theories known as Objectivism and Subjectivism. While Subjectivism does not hold much influence in broader culture today, Objectivism, as they explain it, has roots 2000 or more years ago and holds deep influence in all areas of modern life. Objectivism suggests, among other things
There is an objective reality, and we can say things that are objectively, absolutely and unconditionally true about it. […] We cannot rely upon the subjective judgements of individual people. Science provides us with a methodology that allows us to rise above our subjective limitations and to achive understanding from a universally valid and unbiased point of view. Science can ultimately give a correct, definitive, and general account of reality, and through its methodology, it is constantly progressing towards those goals. (Metaphors We Live By, p 187)
Objectivism holds immense power in our society, being the dominant underlying framework across “science, law, government, business and the media” according to the authors. The implications of this view of truth is that there are absolute truths that exist independent of humans, and using science we can obtain those truths.
While reading these definitions in Metaphors We Live By, I immediately thought of Diana E. Forsythe’s wonderful ethnographic study of AI developers in the 90s Studying Those who Study Us. Where today’s ML tools are trained on massive corpuses of data to build their models, in the 90’s the data was gathered through structured interviews, and then the “automated” systems were designed to guide a user through a series of questions towards a statistically likely “solution.” Forsythe embedded with a team that was tasked with building such a system for medical diagnosis, and she made an observation that has stuck with me since I first read her book Studying Those Who Study Us years ago:
To many researchers in AI, this project [research project to embed “common sense” into AI] makes obvious sense. Since they tend to see knowledge as “out there” and as universal in nature, building a generalized commonsense knowledge base seems to them a challenging but meaningful and worthwhile goal. In contrast, anthropologists typically react to this idea as absurd; given the anthropological view of commonsense (and other) knowledge as cultural and therefore local in nature, the notion of universally applicable common sense is an oxymoron. (Studying Those Who Study Us, page 21)

Studying Those Who Study Us
Copyright 2002, Stanford University
Tech Industry
To frame this observation in the language of Metaphors We Live By, the computer scientists building AI systems in the 90’s believed that they were simply cataloguing the objective truths of reality for a given medical domain, while Forsythe, approaching their project as an anthropologist, saw that their project to gather the “facts” necessary to make a medical diagnosis was not at all objective, because the computer scientists came to the project with strong pre-existing beliefs that they were unaware of. These beliefs manifested (as explored in the ethnographic studies in her book) as a set of assumptions of what counted as relevant knowledge (facts that fit into a computer database and could be obtained by true/false questions) and what was irrelevant (nurses’s knowledge, external factors, anything observed or gained through “soft skills”). In Forsythe’s analysis, these unconscious beliefs led the AI practitioners to build a set of tools that captured all the Objective Knowledge they had acquired, but those tools were useless for the intended audiences because the results they produced were inaccurate or irrelevant. This disconnect between the computer scientist’s beliefs about Objective knowledge and what was actually useful for people they were designing for stemmed from their misunderstanding of how knowledge works.
As Forsythe goes on to document, those in the field of AI research did not see this lesson, nor understand their failures as due to choices they had made. Instead, their assumptions remained fixed, they just pursued making the technology more powerful via more data. Thanks to a few decades of computing power advances, we are now playing with ML tools that have all the same starting premises that Forsythe critiqued, only operating at a much larger and more general purpose scale. Today’s ML Tools are premised on algorithms first developed decades ago, that encode an Objectivist belief in how reality works, a belief that continues to support the idea that knowledge is “out there,” as Forsythe puts it.
Metaphors We Live By counters objectivism by proposing a third view of truth that stands amidst Objectivism and Subjectivism, which they call the Experientialist synthesis.
An experientialist approach also allows us to bridge the gap between the objectivist and subjectivist myths about impartiality and the possibility of being fair and objective. The two choices offered by the myths are absolute objectivity, on the one hand, and purely subjective intuition, on the other. We have seen that truth is relative to understanding, which means that there is no absolute standpoint from which to obtain absolute objective truths about the world. This does not mean that there are no truths; it means only that truth is relative to our conceptual system, which is grounded in, and constantly tested by, our experiences and those of other members of our culture in our daily interactions with other people and with our physical and cultural environments. […] What the myths of objectivism and subjectivism both miss is the way we understand the world through our interactions with it. (Metaphors We Live By, page 193)
Here, Lakoff and Johnson lay out their perspective (which is thoroughly supported in the book and in the 43 years since publishing has only grown stronger) that truth is not absolute and objective, rather it’s experiential, and we are all always updating and and modifying our understandings of the world based on our experiences in it. This is the same perspective that Forsythe refers to when she states that knowledge is cultural.
If this is how knowledge and truth works for humans, and this idea is counter to an Objectivist perspective of knowledge and truth as argued by Lakoff and Johnson, then what does it mean for us that these powerful new ML tools all encode a false view of how humans think and communicate? While I think this is a still unanswered question, I think we can further apply lessons from Metaphors We Live By to begin to guess at an answer.
Culturally, we have some strong myths around computers and data (the key ingredients for ML tools). Myths, in this case, does not mean stories that are false, but stories that inform how we think about the subjects. These myths tell us computers work faster than humans, they are more reliable, more logical, and thus more accurate in their calculations. Data, especially in the sense of “big data” is understood to help us make better decisions and be more objective in sorting through complex problems. There are so many books (I love to read them lol) that seek to complicate or undermine these myths, but they are propped up by lots of money, power, and existing systems. Our myths are cultural stories that tell individuals how to understand what computers do and what they are good for.
These cultural myths also influence how we explain our interactions with computer systems. User experience researchers might be familiar with one impact of these myths: because computers are seen as rational and powerful, people often blame themselves when something goes wrong. “If a computer is so smart and rational, then errors or mistakes must be my fault” is the implicit story, whether or not it is an accurate explanation of the current events. A not-insignificant part of software design is trying to figure out all the ways that users experiences of software can go awry, and trying to help them understand why and what can be done about it. There are, unfortunately, no universal rules for handling this because everyone’s experience of reality is subjective, based on their experiences, with no external, objective reality to appeal to (this is a key argument in Metaphors We Live By). This lack of universal experience is one big reason why designing software interfaces is so complex: human communication is hard.
Knowing this makes me wonder: how the hell will people make sense of these exciting new tools that are clearly more powerful for specific tasks than anything else they’ve used, but also can’t be trusted to be accurate? Here’s an example that Ted Chiang highlights in his piece:
Let’s go back to the example of arithmetic. If you ask GPT-3 (the large-language model that ChatGPT was built from) to add or subtract a pair of numbers, it almost always responds with the correct answer when the numbers have only two digits. But its accuracy worsens significantly with larger numbers, falling to ten per cent when the numbers have five digits. Most of the correct answers that GPT-3 gives are not found on the Web—there aren’t many Web pages that contain the text “245 + 821,” for example—so it’s not engaged in simple memorization. But, despite ingesting a vast amount of information, it hasn’t been able to derive the principles of arithmetic, either. A close examination of GPT-3’s incorrect answers suggests that it doesn’t carry the “1” when performing arithmetic. The Web certainly contains explanations of carrying the “1,” but GPT-3 isn’t able to incorporate those explanations. GPT-3’s statistical analysis of examples of arithmetic enables it to produce a superficial approximation of the real thing, but no more than that.
Culturally, we understand that computers are better at math than humans. Heck, a “computer” used to be a person who did calculations all day, and the original hardware computers were so exciting because they could automate that labor. Their purpose was to be faster and more accurate at math than people. And yet ChatGPT, for all its power and magic, sucks at math. What exactly is a person who only understands computers and software through cultural myths supposed to do with that? Our myths tell us that computers are smarter than us, that big data (which is what “AI” is built on) makes things more accurate. The hype around ML tools absolutely leverages these myths to make the case that they are ushering in the future, that the world is going to change, that new powers are suddenly available to us. If I believe those stories to be true, and I ask the ML tool what 420 plus 666 is, when it responds 986, while a calculator responds 1086, surely the more powerful technology is more accurate, right?
Humans, according to Metaphors We Live By, communicate by leveraging shared concepts that are structured metaphorically. That structure can leverage other metaphors and concepts to enrich the concept. An example used in the book is “more is up” wherein the concept “more” is metaphorically understood to be positive, or “up.” Because we make sense of the world through lived experience, which informs our conceptual metaphors, our understanding of the world is always evolving. This is also happening at the cultural level; new concepts emerge and acquire metaphorical understandings (the internet is a web or a cloud) develop around them. This is human intelligence. Right now, the people producing ML tools are really hoping that these tools will be culturally conceived of as “intelligent,” and all that this metaphor entails (intelligent beings think, evolve, care, etc). But what kind of intelligence can’t ever adapt to new information, or change its understanding of the world? What kind of intelligence doesn’t actually understand anything it is saying?
The “intelligence” metaphor is further encouraged by the interface for many of the biggest ML tools: a chat box. Chat boxes have long been our interface for speaking to other humans, which means we have learned to presume that the entities we’re interacting with have some core set of capabilities for understanding us. We can, through effort, metaphor, and clarification, try to arrive at mutual understanding via communication through text boxes. If you’ve spent time talking to other people (friends, family, strangers) via chat interfaces (text messages, discord, AIM, whatever) you know it can be very difficult to clearly communicate via this medium, but it is possible, as long as the other parties are willing to work with you towards understanding. But, as I already mentioned, ML tools do not, and cannot understand us, they just generate statistically likely results for the given input.
In one of the more interesting insights for me in Metaphors We Live By, the authors point out that the metaphors we use to understand a concept both elucidate and hide certain aspects of that concept. If we decide to use a different metaphor, we can understand different aspects of the concept. The examples are plentiful. They talk about the concept of love; if two people understand love to be a partnership, that leads those people to think about their relationship in a specific way, with specific responsibilities and possibilities. But if love is conceptualized as an unknowable mystery, the metaphor does not make it clear that love involves responsibilities. It instead suggests that each person has no responsibilities; the mystery will unfold as it will. Our metaphors help us make sense of the world, but the metaphors are not objective truths; we can always choose different metaphors.
Campos, in their “Retrospective on a dying technology cycle” post, also resists the term Artificial Intelligence and all that it entails. They name ML tools as a “Pattern Synthesis Engine.” This is far more clarifying a name than “Artificial Intelligence,” because it attempts to clearly name what the tool does. The name avoids the deception of the “intelligence” metaphor, and instead uses an engine metaphor, which entails thinking about ML tools as machines. Machines are understood to be designed for a specific task. In this case, the task is “pattern synthesis” which definitely clarifies what is happening when a user types in an input. This new metaphor is much more conceptually helpful. Unfortunately, it’s also a lot less sexy and has very little history in Science Fiction, so all the people who are hooking their fortunes to the success of these ML Tools have no incentive to rebrand.
In the coming months and years, more and more people will be encountering these deceptively misnamed tools, making sense of them through cultural myths about how computers work, and interacting with them through interfaces that conceptually suggest human capabilities that don’t actually exist. The ML tool makers have encoded Objectivist ideas of language and understanding into their products, ensuring that, unless something radical happens, the easiest conceptual understanding of the tools for most people will always fundamentally be incompatible with their actual capabilities. This seems to me like a disaster waiting to happen.
My most naive hope is that the “intelligence” that ML Tool makers are selling is quickly proven to be untrustworthy, that this flaw makes the deceptive naming and marketing untenable, and work to reconsider what these tools are actually worthwhile for. We surely have the intelligence to do this, but who knows if we have the will.



